
The Data Lifecycle: From Creation to Secure Destruction
Protecting data. It sounds easy, right? The problem is the data keep moving and it's hard to keep track. Let's take a look at how we can handle it and keep the data safe at all times!

Information security is, at its core, about protecting data.
Shocking, right?
But here’s the catch: data isn’t static. It moves, it grows, it changes hands, and if you’re not careful, it can turn against you.
Think about it:
You toss out an old hard drive, “delete” the files, and suddenly your data lives on in someone else’s hands.
You keep buying more storage, but over time your systems get slower and slower because of all the forgotten data
Data doesn’t just exist. It has a life.
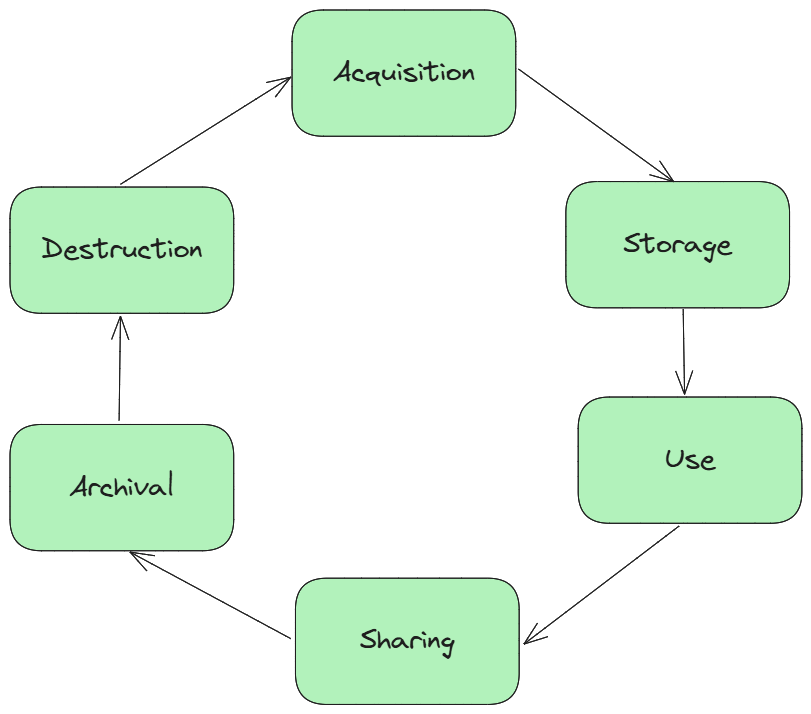
And every stage of that life: birth, use, storage, sharing, retirement comes with its own risks.
That’s why security professionals rely on the data lifecycle: a framework to make sure information stays protected from the moment it’s created until the day it’s destroyed.
Data Life Cycle
There isn’t just one “official” data life cycle model. Different sources describe it in slightly different ways.
For this newsletter, I’ll use the model from the CISSP preparation materials, since that’s our main focus here.
Let’s break it down phase by phase.
Data Acquisition
Well, the first thing we need to do is to create or acquire the data.
Generally speaking, data is acquired by an organization in one of three ways:
Collected directly – e.g., a customer fills out a registration form, an employee clocks in with a badge, or a sensor records temperature in a warehouse.
Copied from elsewhere – e.g., importing a supplier’s product catalog, downloading data from a government open-data portal, or syncing customer records from a partner system.
Created from scratch – e.g., a financial analyst builds a forecast spreadsheet, a developer generates test data for an application, or a marketing team creates a new customer segment list.
Data Collection
The bad news? Data Collection is where things get tricky.
Once data is acquired, it doesn’t just float around randomly. It needs to be collected and organized so the organization can actually use it.
But here’s the catch: we must be careful about what we collect, especially when it comes to personal data.
In general, organizations should collect the minimum amount of personal information required to perform their business functions. Anything beyond that isn’t just wasteful.
It’s a liability.
Privacy laws differ around the world:
In the EU, strict regulations like GDPR heavily limit what data can be collected.
In the US, restrictions are lighter and vary by state.
In China, there are virtually no limits on data collection.
We won’t dive into specific laws today, but it’s worth mentioning that the types of data your organization collects, and how it’s managed throughout its lifecycle, must be clearly defined in explicit, written policy.
Data Storage
Once collected, data has to live somewhere, usually in databases, file servers, or cloud systems. This is the “warehouse” phase.
Examples:
Customer details stored in a CRM.
Employee contracts kept in an HR system.
Medical records saved in a hospital database.
But storage isn’t just about dumping data in a folder. Metadata is usually added at this stage:
Business metadata – who owns the data, what it’s used for, and its classification (public, internal, confidential, restricted).
System metadata – when it was created, who accessed it last, or how it’s backed up.
This metadata is critical because it allows organizations to apply policy controls:
Who can access the data (and under what conditions).
How long the data should be retained before being archived or destroyed.
Which compliance rules apply to that dataset.
Risks: If storage isn’t secure, you end up with exposed databases, weak access controls, or unencrypted backups that attackers can easily exploit.
Takeaway: Encrypt it, back it up, and restrict access. Stored data is valuable, but only if it’s protected.
Data Use
After data is acquired and stored, it’s finally time to use it!
And let’s be honest, that’s why we have it in the first place. But from a security perspective, this is also the trickiest stage.
You want the information available, but only to authorized users, and you want only those users to modify data in approved ways.
That’s not even the hardest part. One of the biggest challenges is ensuring consistency with internal policies and regulatory requirements.
For example, adding a single piece of sensitive information to a document can change its classification. That means every modification must be tracked, and the data must remain compliant with both internal rules and applicable laws. Achieving this in practice is far from easy.
Takeaway: Data use is a balancing act, make it accessible for legitimate purposes while enforcing strict controls and compliance checks.
Data Sharing
I don’t think you’ll be surprised to hear that modern companies share data all the time: with employees, contractors, suppliers… you name it.
Information sharing is a key enabler of today’s supply chains and business operations.
But here’s the catch: while sharing data is necessary, doing it wrongly can have serious consequences. The wrong recipient, an insecure channel, or a breach of policy can cost you everything: reputation, money, or even legal compliance.
Best Practices:
Share only what’s necessary and only with authorized parties.
Use secure channels and encryption for sensitive data.
Keep clear records of who has access and why.
Ensure third-party agreements cover confidentiality and compliance.
Takeaway: Data sharing fuels business, but only if it’s controlled, secure, and aligned with policies and regulations.
Data Archival
At some point, the data in our systems will stop being used regularly.
So what do you do? Just delete it, right?
Why pay for extra storage when it’s not actively needed?
Well… not so fast.
There are many reasons why data should be kept around for a certain period:
Legal and regulatory requirements: Financial, healthcare, or government records often need to be retained for years.
Business continuity: Historical data can help with audits, reporting, or trend analysis.
Investigations and compliance: Archived data can be critical during internal investigations or regulatory reviews.
Archiving isn’t just “put it in a folder and forget it.” It requires:
Proper classification so you know what data is sensitive and what isn’t.
Secure storage — even archived data can be a target for attackers.
Retention policies that define how long data is kept and when it should be destroyed.
Takeaway: Archival is about balancing storage, compliance, and security. Keeping data too long is a risk, but deleting it too soon can also have serious consequences.
Data Destruction
Finally, the nightmare is over.
We’re ready to get rid of the data. No more storage costs, no more worries about compliance… right?
Well, if you believed that, I just got you!
Deciding that data is no longer needed doesn’t mean you can just click “delete.” Proper destruction is essential to prevent leaks, breaches, or legal issues.
This can involve different techniques depending on the media:
Physical drives: wiping, degaussing, or shredding.
Cloud or virtual storage: secure deletion processes that ensure data cannot be recovered.
We’ll dive deeper into these techniques in a future post. For now, remember: proper destruction is a critical part of the data lifecycle and is mandated by many standards and privacy laws.
Summary
If you’ve made it this far, congratulations! The data lifecycle is a core concept in information security, and understanding it is more valuable than it might first appear.
On the surface, it can seem boring, but once you realize how many systems and processes rely on this framework, and how much risk it helps prevent, it suddenly becomes very relevant.
Thank you for reading my newsletter and see you next week!
If you want to follow my CISSP journey and explore more practical insights like this, subscribe to my newsletter and join me as we break down complex cybersecurity topics one step at a time.
Glossary
Data Lifecycle – Framework describing all stages of data from creation to destruction.
Data Acquisition – Process of creating, collecting, or copying data for use.
Data Collection – Organizing and gathering data to ensure accuracy and relevance.
Data Storage – Safely keeping data in systems, databases, or cloud environments.
Metadata – Information about data, including ownership, classification, and system attributes.
Data Use – Accessing and processing data while maintaining security and compliance.
Data Sharing – Exchanging data with authorized parties securely and in compliance.
Data Archival – Retaining inactive data for legal, business, or compliance purposes.
Data Retention Policy – Rules defining how long data is kept before destruction.
Data Destruction – Secure elimination of data to prevent unauthorized access or leaks.
This is a fantastic breakdown of the data lifecycle!
I love how it emphasizes that data isn’t static, it truly has a “life” with risks at every stage. The emphasis on balancing usability, compliance, and security really hits home, especially in today’s cloud-first, data-driven world.
Looking forward to your deep dive on secure destruction techniques!